Legislative Debate Video Analytics
Legislative Debate Video Analytics
Big Data Processing · Multimodal CV/NLP · Clustering & Embeddings
I completed this project during the 2024 legislative elections in Portugal as part of the Big Data Processing course. The goal was to analyze video frames from televised election debates and extract structured signals—objects, facial emotions, and frame embeddings—to study content and attempt to separate identities and scenes via clustering. The debate used for the project featured André Ventura and Mariana Mortágua. Final grade: 8/10.
Problem & Goal
Election debates contain repeating visual patterns (candidate close-ups, split screens, candidate + presenter shots). Our goal was to build a pipeline that:
- Extracts frame-level features (detections, faces, text, emotion, embeddings)
- Uses embeddings to group visually similar frames/faces
- Applies clustering to separate candidates / presenter / mixed scenes
- Visualizes results to validate whether clusters match real debate structure
Approach
1) Multimodal frame extraction
For each frame we extracted:
- Object detections (e.g., person, tie, TV, laptop)
- Face crops + facial emotion recognition (FER categories like Neutral, Surprise, Sadness, etc.)
- OCR text (when available)
- Embeddings to represent frames/faces for clustering and retrieval
2) Candidate/scene identification via embeddings + clustering
To estimate which frames correspond to which person/scene, we used embeddings and clustering.
Expected number of clusters: 6
Because debates typically contain recurring shot types:
- Candidate A alone
- Candidate B alone
- Presenter alone
- Candidate A + presenter
- Candidate B + presenter
- Multi-person / “everyone” / split-screen shots
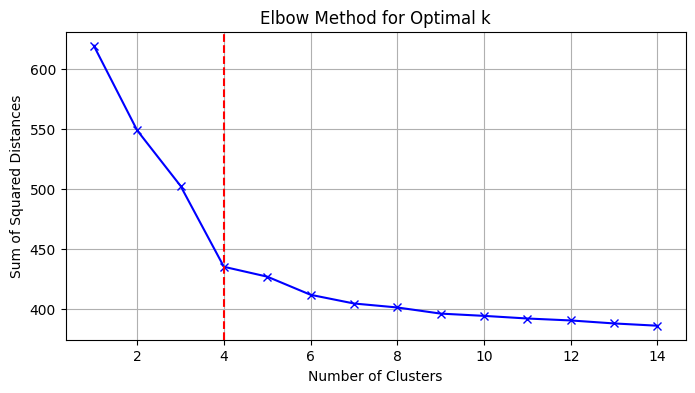
3) Choosing K (Elbow Method)
We applied the elbow method to estimate a reasonable number of clusters for K-Means: we look for the point where increasing k yields diminishing returns in within-cluster distortion.
4) Clustering algorithms explored
- K-Means — used with the elbow method to pick the number of clusters
- Spectral Clustering — produced a strong, stable separation in practice
- DBSCAN — identified outliers (noise), but was sensitive to parameters and tended to create too many clusters
- Isolation Forest — used for outlier detection / preprocessing (not clustering itself), which affected downstream clustering outcomes
- t-SNE visualization — used to project high-dimensional embeddings to 2D for interpretability and qualitative validation of cluster structure
Results & Visual Diagnostics
Emotion and object statistics



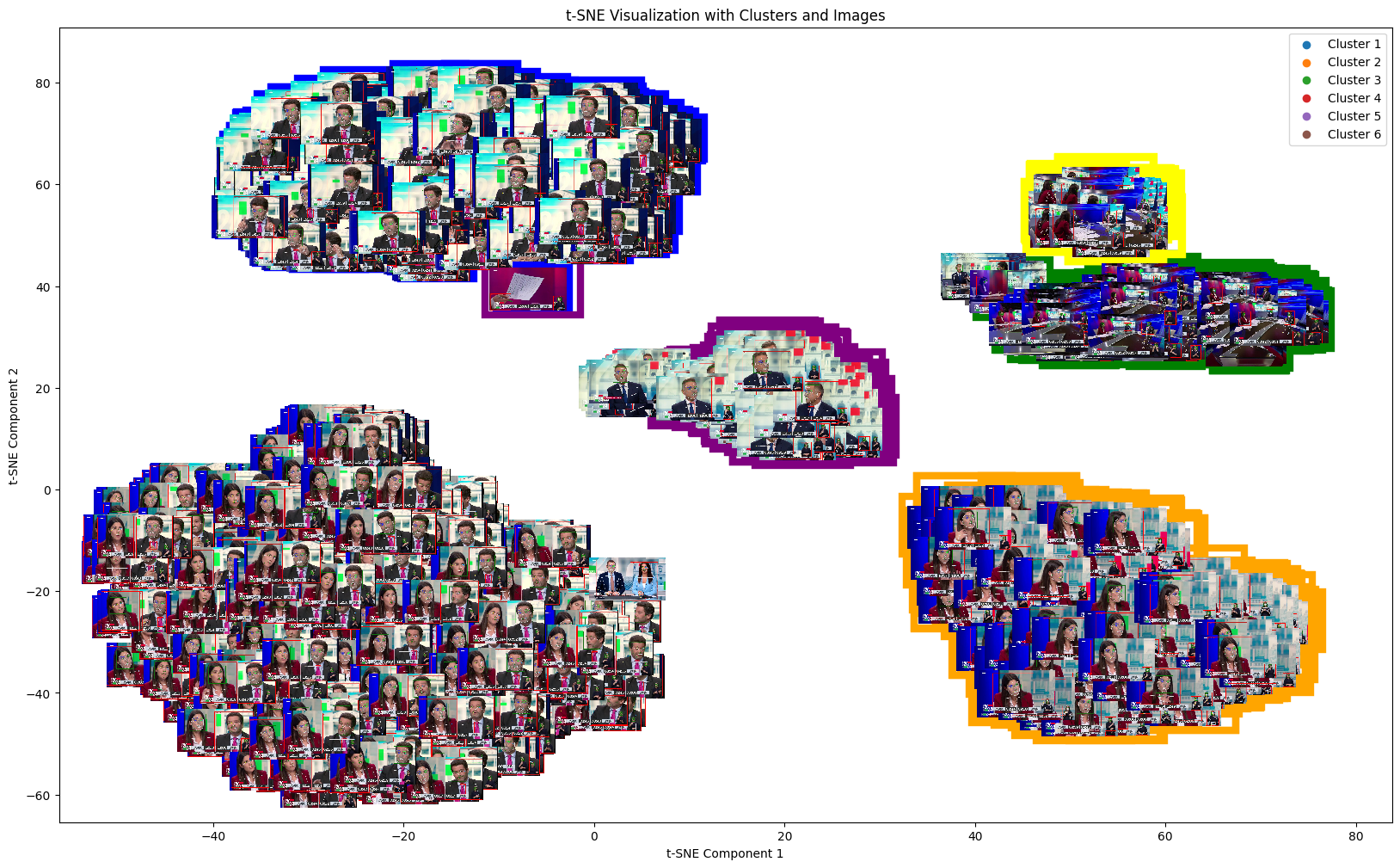
Spectral clustering (strong baseline)
Spectral clustering produced a reliable division of embeddings into visually consistent groups, aligning well with repeated debate shot patterns.
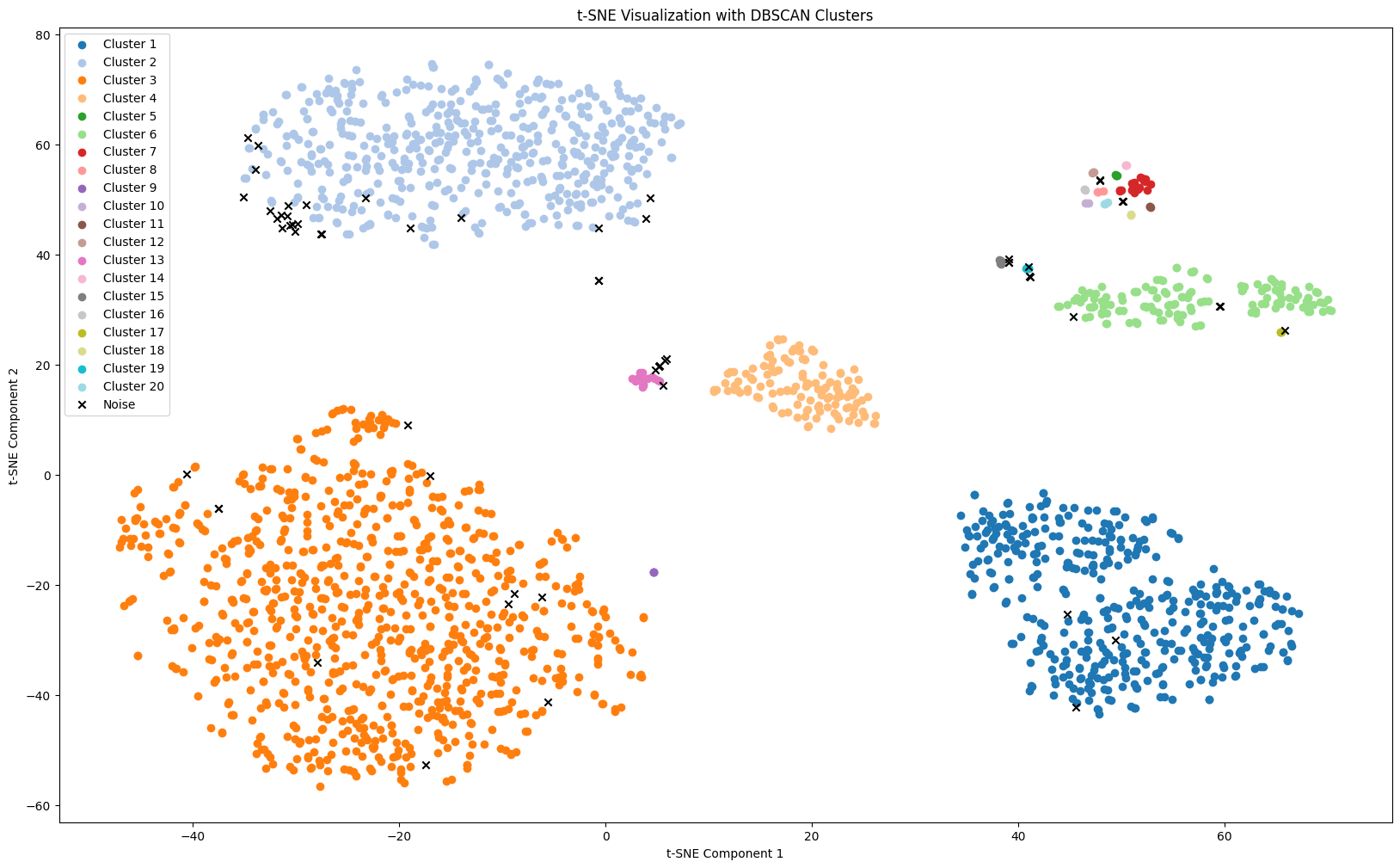
DBSCAN (best outlier handling, but over-clustered)
DBSCAN was even better at identifying outliers (noise points), but it over-segmented into too many clusters—likely requiring tighter parameter search (eps/min_samples) to match the expected debate structure.
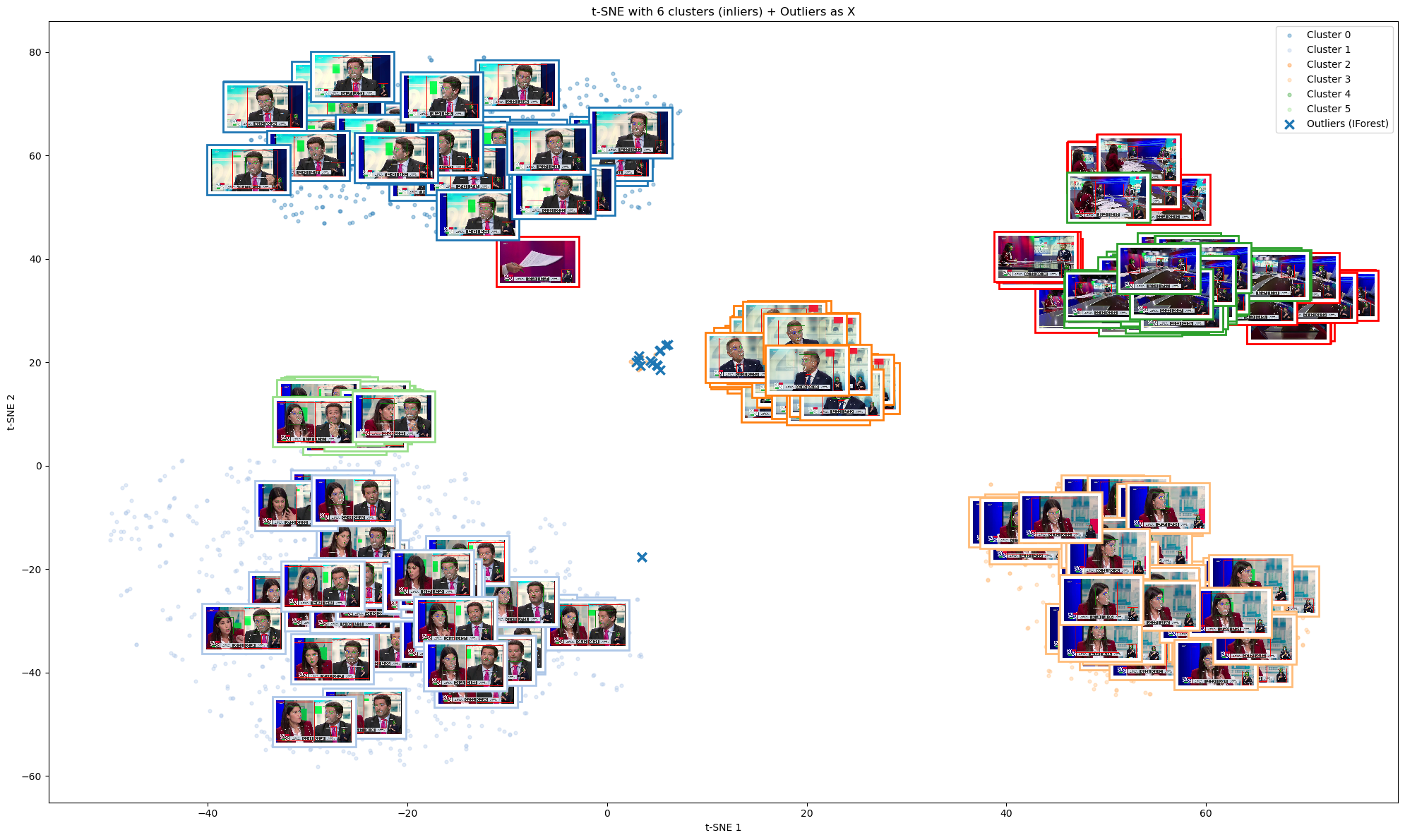
Isolation Forest (outlier preprocessing, fewer clusters)
Isolation Forest helped detect outliers, but in our case it resulted in fewer clusters than expected (some shot types were merged). Despite that, the key candidates/scenes were still recognizable.
Conclusion
This project gave me hands-on experience building a multimodal data pipeline, using embeddings for unsupervised identification, and validating clustering quality through both quantitative heuristics (elbow method, parameter tuning) and visual diagnostics (t-SNE + cluster image grids).
Qualitative identity check
Using embedding-based clustering, the system identified the two candidates correctly the majority of the time, especially in stable close-up shots.


Project Information
- Category Big Data Processing
- Methods Multimodal CV/NLP, Clustering, Embeddings
- Course Big Data Processing
- Year 2024
- View on GitHub